.webp)








.webp)
.svg)




TL;DR
Claude is excellent at one question, one dataset, one moment. It breaks the day you try to make it a system that runs every week. We built our entire product on Claude. We know exactly where the line is.
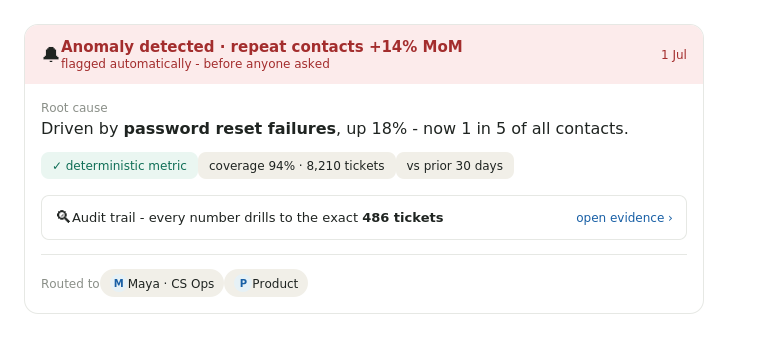
Tuesday morning. You closed 41,000 tickets last quarter. The QBR is in nine days. Your CEO wants to know why repeat contacts went up 14%.
You open Claude Code. You paste in a CSV of 5,000 tickets. You ask it to tag them and find the top themes. Twenty minutes later you have a clean table and a summary that sounds smart. You wonder why you pay a vendor for this.
Quick disclosure. I am the Head of Demand Generation at SentiSum. I have a bias and I will own it. But here is what makes this worth your time. We built our entire product on Claude. A year, a real engineering team, in production, in front of regulated customers. I am not guessing where the model stops being the hard part and the system starts. I lived it.
The model is excellent. That is not the question. The question is the distance between a model that answers once and a system you can actually run a function on. The distance is bigger than the demo suggests.
What Claude can actually do for a CX leader today
Let me not undersell it. With Claude, and tools like Claude Code or Cowork on top of it, a CX leader with a CSV and no data team can do real work that used to need engineering.
- Pull the top three contact reasons from 8,000 tickets in twenty minutes. A clean table, ready for a meeting. A platform is overkill for that.
- Test five taxonomies against the same data before you commit to one. Keep the one that holds.
- Write the glue code. Pull from Zendesk, join NPS from Delighted, drop it in a Sheet. An afternoon.
- Pressure-test a hypothesis. Did pricing complaints rise after the price change? Ten minutes. One defensible-enough answer for an internal call.
- Turn a messy export into a first-pass exec summary you then edit.
One question. One dataset. One moment. Claude is the right tool. Use it. We do, every day.
The trouble starts the day you try to make it a system. Something that runs every week, that other people depend on, that has to be right when someone important asks.
The 20 minutes you see, and the system you don't
The demo works on day one. That is the trap.
It works on the dataset you handed it, the question you asked, and the meeting you have Thursday. The model is doing maybe 10% of the job, beautifully. That 10% is the only part you see in the demo. The other 90% is everything underneath.
None of it is the model being dumb. All of it is the system around the model. The part that does not fit in a prompt. The part that does not show up in a weekend. The part that is actually the work.
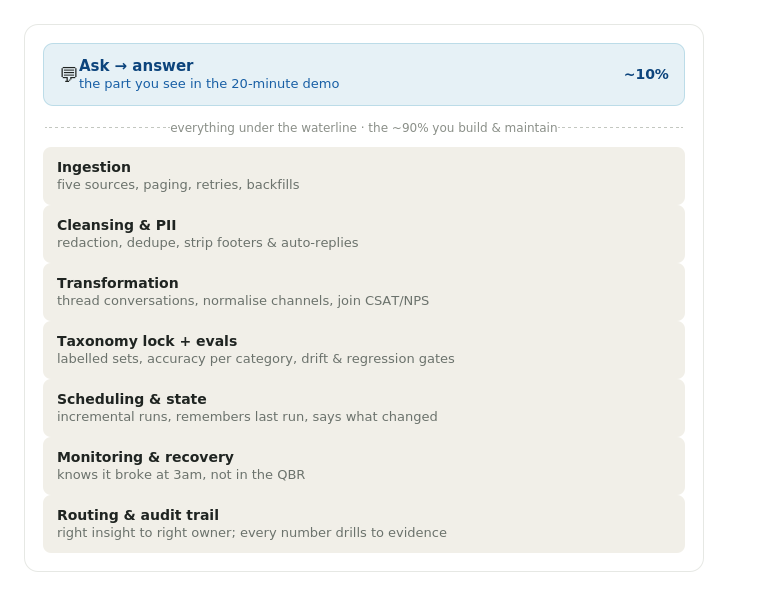
The pipeline is the job. And nobody applauds for the pipeline.
Your demo ran on 5,000 clean tickets in a tidy CSV. Production is not that.
Production is 200,000 records a month across chat, email, app-store reviews, call transcripts, and an NPS tool. Each one has a different schema. Each one has a different idea of what a "ticket" is. Each one breaks in its own way. Before the model sees a single word, someone has to:
- Ingest and keep ingesting. A connection that pages, retries on failure, and backfills the day it was down. Then four more sources just like it.
- Cleanse the mess. Redact PII before it hits a model. Dedupe the same conversation arriving twice. Strip the signatures and auto-replies that otherwise become your top "theme." Handle emojis, agent shorthand, and a customer who writes "yes thx" to a question you cannot see.
- Transform into something comparable. Thread a 9-message email chain into one conversation. Normalise "chat / Chat / livechat" into one channel. Join a CSAT score to the right ticket. Reconcile timezones.
- Survive change. Zendesk renames a field. A product line launches with new tags. The transcription vendor changes format. Every one of these silently breaks the weekend script. You find out when the number looks wrong in a meeting.
We spend far more engineering on this substrate than on the model. Here is the uncomfortable truth we learned early.
Garbage in does not give you garbage out. It gives you confident, plausible, well-formatted garbage out. Which is worse. Because nobody questions it.
How do you actually know the answer is right?
This is the question that separates a script from a system. Almost nobody asks it at the demo.
A prompt has no test suite. You ran it. The answer looked smart. You shipped it. But "looked smart" and "correct" are different things. At 200,000 records you cannot eyeball it. To trust the output you need the machinery under any real ML system.
- A labelled evaluation set, so you can measure accuracy per category instead of going on vibes.
- Regression tests that fail the build when a change quietly drops "refunds" accuracy from 91% to 78%.
- Drift detection. The same prompt on a new month re-decides your categories. 18 themes in January. 22 in April. Three of them just January themes with new names. Your dashboard now compares "delivery delays" to "shipping issues" as if they are different problems.
- Coverage honesty. A metric computed on the 37% of tickets that had the field populated, displayed as if it covered 100%, is a landmine. Never show a number without its denominator.
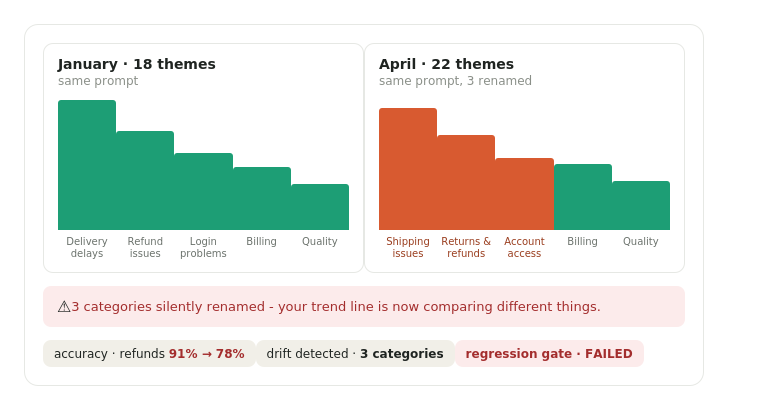
Here is the lesson that cost us the most. Every definition needs a test pinned to it. Every correction a customer gives you has to become a permanent, tested fact. Otherwise you re-litigate it every quarter.
A prompt forgets. A system remembers, and proves it still works.
A live system is a different animal than a one-off
A CSV analysis is a photograph. A function is a film.
The moment "run it once" becomes "run it every day without me," you have signed up for a longer list than you scoped. Scheduling. Incremental processing. State so you can say what changed, which is the entire point. Monitoring that tells you the pipeline broke at 3am rather than in the QBR.
The weekend script has none of this. Bolting it on afterwards is the project nobody scopes and everyone underestimates.
Catching the spike before someone taps you on the shoulder
A dashboard waits for you to open it. A colleague taps you on the shoulder. The difference between them is detection.
A real system watches the drivers, the queues, the segments. It surfaces the one that moved before it becomes a QBR question. Two cautions we paid for the hard way.
First, an alert on noise is worse than no alert. People stop reading the channel.
Second, and subtler. If the underlying number is regenerated each run, you will alert on phantom spikes. Movement only means something when the metric is computed deterministically. Otherwise "CQS dropped 9% this week" might just be the model re-scoring last week's tickets a little differently.
Insight without routing is expensive trivia
You found that 12% of contacts last month were about a broken checkout flow. Now what?
Does product see the product issues? Does ops see the fulfilment issues? Does the agent on the floor see the trend before the next call about it lands in their queue?
In most DIY builds the insight dies as a message in #cx-insights. Three thumbs-up. Zero follow-through.
Getting the right finding to the right person, and only that finding, needs a system that knows who cares about what. That is not a prompt. That is a model of your org sitting next to your model of your customers.
The number that has to survive the CFO
Your CFO asks why churn rose 3%. You say late deliveries, from the analysis. They ask how you know. You say the AI tagged it.
That is the moment prompt-based analysis falls over. No audit trail. No way to show how a ticket got classified. No defence.
Here is the discipline that took us the longest. The model reasons, the engine computes. The model never hand-writes a number into a summary. It narrates. A deterministic engine produces the figure. Every figure drills straight to the tickets behind it.
If your numbers ever have to defend themselves in a board deck, an OKR review, or a regulator's inbox, this part is the difference between a tool and a function you can run a business on.
Three questions to make the call
Answer all three the same way and the call gets easy.
One-time question or ongoing operational need? One-time means you ask, you get the answer, you move on. Ongoing means the answer changes every week and someone needs the new version without asking. Claude is built for the first. VoC platforms exist because of the second.
Defensible number or directional fine? For exploring, directional is fine. For a board deck, an OKR, an investment decision, or a regulator's inbox, the number has to defend itself. A prompt cannot do that.
Who maintains this in six months? Name the person. Not the role. The person who owns the pipeline when the Zendesk API changes. The person who owns the taxonomy when a product launches. The person who owns the eval set when accuracy slips. If you cannot name them, the build will break and nobody will fix it. That is not a knock on your team. That is how every script in every company eventually dies.
When you should just build it yourself
Here is when DIY is genuinely the right call. You are a 50-person company. Under 2,000 tickets a month. One engineer with spare cycles. You need the top five reasons people churn, well enough to act on, not well enough to defend in a boardroom.
Build it. A platform is the wrong purchase for you right now.
The line is not 50 people versus 5,000 people. The line is operational stakes. If a wrong answer costs you a Slack thread, build it. If a wrong answer costs you a board conversation, a product bet, or a compliance finding, do not.
The honest verdict
Claude is the right tool for a question. A VoC platform is the right tool for a function.
The model was never the hard part. It is excellent. It does the visible 10% brilliantly. The hard part is the 90% underneath. The pipeline. The evals. The live system. The alerts. The routing. The audit trail. We spent a year building that around Claude. Most teams should not have to.
If your customer feedback analysis is a project, build it. Use Claude. It is great at it.
If it is a function, the question was never whether the model is good enough. It is. The question is whether you want to spend the next year building everything around it.
If you are somewhere in the middle and want a sanity check, book a 30-minute call. No demo. No deck. We have watched teams try every version of this, and we built it ourselves. I will tell you honestly whether you should build it or buy it for your specific situation.
Frequently Asked Questions
Explore Real Success Stories
Explore Success Stories
Talk to a Data Expert




