.svg)


Customer support conversations are rich, lengthy, and come in high volumes.
Which makes them both a goldmine of customer insight and a complex, painfully difficult task to tag and categorize.
Natural language processing (NLP) is an effective solution for overcoming this challenge.
The right NLP can process large volumes of speech and text in real-time, providing accurate, consistent and granular insights that can be leveraged to optimise processes and drive CX improvements.
However, not all NLP is equal.
It's a broad term and the outcomes of different NLP softwares vary significantly in usefulness and accuracy.
In this short article, we'll review the different types of NLP and make the case for why machine learning-based NLP is the best solution for tagging automation.
Three types of NLP...what's the difference?
NLP is how we can get computers to understand language—speech and text.
One of the main benefits of having a computer understand human language is that, unlike humans, they are incredibly fast, consistent and unbiased in their approach.
When software processes text in large batches—let's say 100,000 support tickets—it can be done in an instant, and the results are actionable.
There are three distinct types of NLP:
1/ Keyword extraction
Providers like Zendesk and Intercom provide this built-in to their help desk software.
A keyword extraction system understands human language by following very specific rules. For example, if the word ‘refund’ is present in a piece of text, the system will tag it as the topic is ‘refund’.
Applied to thousands of support queries, this method is flawed.
What if a customer says ‘can I get my money back?’ instead of ‘can I get a refund?’. It wouldn’t tag the topic correctly.
What if a customer said, ‘I don’t want a refund, but I’m not happy.’ This would be incorrectly tagged ‘refund’.
The result is that a ‘keyword extraction’ system largely outputs inaccurate support ticket tags.
Getting meaningful results is also difficult because to improve accuracy, your tags must be high level. For example, many companies have just four categories like 'delivery', 'refund', 'request', and 'bug', rather than granular reason for contact tags.
When tags are high-level, uncovering actionable, insights requires a significant amount of manual analysis on top of the simplistic keyword-base categorisation.
Another core flaw in the way Zendesk and Intercom tags support conversations is that they only tag the very first message automatically. That means if the customer doesn't mention all the topics they are going talk about in that first message, your reporting will never know.
2/ Rule-based NLP
Rule-based NLP has improved accuracy relative to keyword extraction.
Unlike keyword extraction, it doesn't only look for the word you tell it to, but it also leverages large libraries of human language rules to tag with more accuracy.
For example, the library of rules tells the computer that ‘liberty’ and ‘freedom’ mean the same thing...so tag both.
A rule-based NLP system simply follows these rules to categorise the language it’s analysing.
As you can imagine, if the rule doesn’t exist, the system will be unable to ‘understand’ the human language and thus will fail to categorise it.
Unfortunately, this means accuracy is dependent on the rules provided. When you have a unique business environment, and want detailed results, it is practically impossible to give the software all the rules required.
3/ Machine learning-based NLP
SentiSum is a machine learning-based NLP system.
A machine learning-based NLP system relies on more modern ‘statistical inference’ techniques.
It's more intelligent and understands speech and text in a similar way to how humans do.
Once it’s learned to understand human language in a particular environment—say, the legal world—it can infer the meaning of misspellings, omitted words, and new words without a human setting up a new rule.
Machine-learning also learns the patterns between phrases and sentences and is constantly optimising and evolving itself so that it’s level of accuracy is getting ever closer to reality.
After some upfront training by SentiSum, we could let it loose on a data set and it would categorise it with increasingly higher accuracy.
SentiSum also reads and re-reads the entire conversation, making sure it picks up all the topics and their sentiment mentioned throughout the entire exchange.
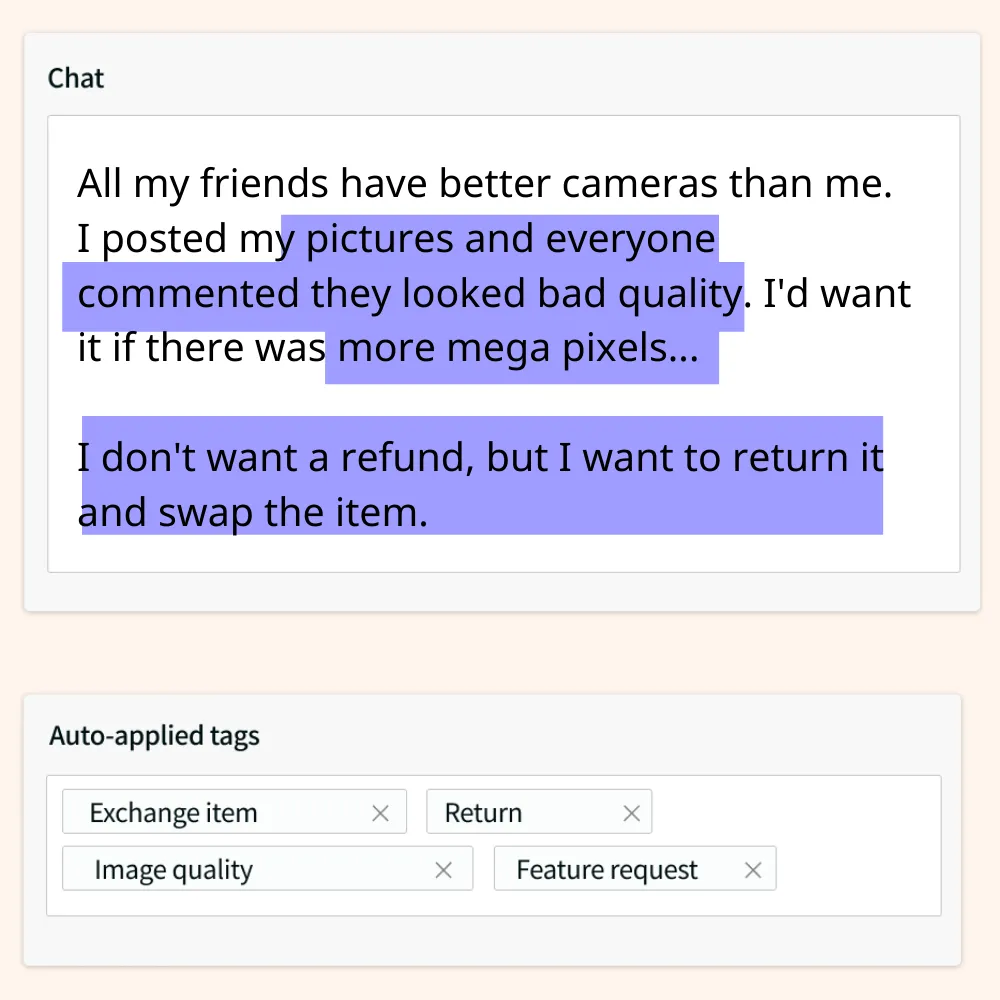
Here are all three in action on a support ticket:

As you can see, keyword extraction and rule-based NLP is simplistic and inaccurate. Over thousands of support queries, the impact is enormous. Machine learning is more intelligent with its tagging, providing much greater accuracy.
Keyword extraction: Blindly tags any keyword it’s told to.
Rule-based: Blindly follows more advanced rules. It might know ‘adjective’ + ‘noun’ indicates a customer's opinion about that noun. So ‘bad’ + ‘quality’, indicates a quality issue for another noun mentioned, ‘camera’, let's tag the topic with ‘camera quality'.
Machine-learning: Doesn’t blindly tag keywords or ‘rules’. It infers meaning based on patterns between words and the wider context of the sentence and paragraph they sit within. In the above example, the last sentence says ‘I don’t want a refund’, machine-learning is the only one to understand this nuance and not tag the ticket with the topic ‘refund’.
Machine learning provides the most accurate, granular ticket tags...but so what?
Once your ticket tags are accurate and granular, they become an incredibly powerful way to drive positive business outcomes in your business.
The positive effects of our ML-based tags can be seen within the support department:
- Reduce manual work for agents and those doing reporting.
- Improving SLA times.
- Automatically route urgent or prioritise support requests.
- Reduce ticket volume to maintain metrics like 'contact per customer'.
- Improve customer satisfaction.
But, our accurate, detailed ticket tags also have a cross-functional impact.
Support conversations are a key resource of customer insight, unlocking that insight with ML-based tags unlocks numerous use cases.
Here are three examples:
- Uncover friction points, churn drivers and prioritise CX improvements.
- Underpin the roadmaps of product and project management teams.
- Let marketing and sales teams deeply understand customers and use that information to create campaigns and new content
Read part 2 below to understand the wider impact of using machine learning to automate ticket tagging.
.webp)
.jpg)





.webp)